
摘要:2023年,生成式大模型ChatGPT的出现给沉寂许久的AI市场添了一把猛烈的火,业界甚至有人将其比喻成“AI的iPhone时刻”。 从ChatGPT诞生起,业内就在探讨它将如何与智能驾驶相结合,近日,毫末将这种设想变成了落地的产品。 4月11日,毫末智行在北京举办了第八届毫末AI DAY,发布了自动驾驶生成式大模型产品DriveGPT。图片来源:毫末智行 DriveGPT如何改
2023年,生成式大模型ChatGPT的出现给沉寂许久的AI市场添了一把猛烈的火,业界甚至有人将其比喻成“AI的iPhone时刻”。
从ChatGPT诞生起,业内就在探讨它将如何与智能驾驶相结合,近日,毫末将这种设想变成了落地的产品。
4月11日,毫末智行在北京举办了第八届毫末AI DAY,发布了自动驾驶生成式大模型产品DriveGPT。
 图片来源:毫末智行
图片来源:毫末智行
DriveGPT如何改变自动驾驶?
自动驾驶行业发展到现在,面临的一个非常大的技术问题在于Corner case(长尾难题)。
从技术的角度看,以往自动驾驶系统认知环境主要靠人工手写规则,但自然界中的场景无穷无尽,相应的规则也没有穷尽,自动驾驶技术的发展非常受限。
为解决这个问题,业内一直在用机器学习替代传统的规则式部分,力求实现端到端的自动驾驶:输入感知数据——机器学习输出规划决策数据。
毫末认为,生成式大模型GPT可以帮助解决认知决策问题,最终实现端到端的自动驾驶。
什么是GPT?
GPT的定义是生成式预训练Transformer大模型,用语言学的逻辑理解,输入一个词,GPT会根据现实中的分布推测下一个该出现的单词是什么,每生成完一个,会把过去的东西加上,当做新的输入猜测下一个是什么,这种生成式模型就可以生成对话。
以中文自然语言为例,单字或单词就是Token,把Token输入到模型,输出就是下一个字词的概率。
而DriveGPT实际上指的是自动驾驶界的生成式预训练大模型,将场景Token化,毫末将其称之为Drive Languag。
Drive Language将驾驶空间进行离散化处理,每一个Token都是场景的一小部分。目前毫末拥有50万个左右的Token词表空间。如果输入一连串过去已经发生的场景Token序列,模型就可以根据历史,生成未来所有可能的场景。
具体解释,只要输入目前的驾驶环境,包括车辆本身的状态、周围障碍物的状态、道路环境等,DriveGPT就会生成未来可能发生的一系列交通状态,就像多个平行宇宙,并根据每一种状态做出不同的决策:前面车辆变道时需要怎么做,不变道时需要怎么做。并且,这种决策会形成完整的证据链。
 图片来源:毫末智行
图片来源:毫末智行
概括来说,毫末认为,DriveGPT雪湖·海若三个能力:
1.可以按概率生成很多个场景序列,每个场景都是一个全局的场景,每个场景序列都是未来有可能发生的一种实际情况。
2.在所有场景序列都产生的情况下,能把场景中最关注的自车行为轨迹量化出来,也就是生成场景的同时,便会产生自车未来的轨迹信息。
3.有了这段轨迹之后,DriveGPT雪湖·海若还能在生成场景序列、轨迹的同时,输出整个决策逻辑链。
在模型优化方面,DriveGPT雪湖·海若主要是通过引入真实人驾接管数据建立RLHF(人类反馈强化学习)技术,对自动驾驶认知决策模型进行持续优化。
此外,还具有场景识别的能力,在毫末智行演示的场景中,普通的解决方案标注一张图片需要大约5远,DriveGPT雪湖·海若只需要0.5元,这个能力将会向行业伙伴开放。
 图片来源:毫末智行
图片来源:毫末智行
另外一点,由于DriveGPT的决策具有完整的逻辑推理链,它也可以提升人机共驾的体验。通过DriveGPT技术,未来人机交互界面(HMI)可以告诉驾驶者,它为什么做出这样的决策,在某种程度上它可以提升用户对自动驾驶系统的信任感。
毫末智行技术副总裁艾锐表示,目前毫末还没有做这样的系统,但理论上看,HMI可以通过语音的方式与驾驶者交流。“我可以把它理解为一个导航意图,你想选一个更快的路还是选一个收费更少的路。从这个角度来说,我觉得DriveGPT后面的想像空间很大。它能实时接收人的反馈之后,也许在大家使用自动驾驶的时候,就不是默默地坐在那里看着了,会有一个更深度的交互。”艾锐说。
毫末如何实现DriveGPT
大模型训练并不是一个简单的事情,毫末也解释了DriveGPT背后需要的能力。
最基础的当然是算力,模型参数规模达到 1200 亿,需要非常强大的算力支持。今年1月,毫末和火山引擎共同发布了其自建智算中心,毫末雪湖·绿洲MANA OASIS。OASIS的算力高达67亿亿次/秒,存储带宽2T/秒,通信带宽达到800G/秒。
还需要训练和推理框架的支持。因此,毫末也做了以下三方面的升级。
1.训练稳定性的保障和升级。
毫末在大模型训练框架的基础上,与火山引擎共同建立了全套训练保障框架,通过训练保障框架,毫末实现了异常任务分钟级捕获和恢复能力,可以保证千卡任务连续训练数月没有任何非正常中断。
2. 弹性调度资源的升级。
由于每天不同时段回传的数据量差异巨大,需要训练平台具备弹性调度能力,自适应数据规模大小。毫末将增量学习技术推广到大模型训练,构建了一个大模型持续学习系统,研发了任务级弹性伸缩调度器,分钟级调度资源,集群计算资源利用率达到95%。
3.吞吐效率的升级。
在传统的训练框架中,算子流程很长,毫末通过引入火山引擎提供的Lego算之库实现算子融合,使端到端吞吐提升84%。
此外,还有一个基础能力就是数据,毕竟DriveGPT雪湖·海若需要引入真实的人驾接管数据来优化模型。
在数据来源方面,毫末公布了智能驾驶产品最新的进展:
截止目前,毫末智能辅助驾驶用户行驶里程已经突破4000万公里。毫末城市NOH在北京、保定、上海等城市开启泛化测试,落地即可体验到毫末的城市NOH功能。
首款搭载HPilot3.0系统的新摩卡车型也即将在近期重磅上市,第二款搭载毫末HPilot3.0系统的车型魏牌蓝山也将在今年年内上市。
同时,乘用车高级别辅助驾驶领域,毫末智行已获得三家主机厂定点合同,相关项目已经在交付中。
不依赖雷达,MANA视觉感知升级
除DriveGPT外,毫末此次还重点介绍了MANA在视觉感知上的进展。
此前,毫末的感知视觉自监督大模型是互监督,用激光雷达作为监督信号训练视觉,目前已经升级到纯视觉。
视觉感知的核心目的是恢复真实世界的动静态信息和纹理分布,因此毫末对视觉自监督大模型做了一次架构升级,将预测环境的三维结构,速度场和纹理分布融合到一个训练目标里面,使其能从容应对各种具体任务。目前毫末视觉自监督大模型的数据集超过400万Clips,感知性能提升20%。
此外,毫末还将鱼眼相机引入视觉BEV的感知框架当中,在泊车场景可做到在15米范围内达测量精度30cm,2米内精度高于10cm。
拥有这些能力之后,毫末开始尝试去掉超声波雷达,在纯视觉三维重建方面,通过视觉自监督大模型技术,毫末不依赖激光雷达,就能将收集的大量量产回传视频转化为可用于BEV模型训练的带3D标注的真值数据。
通过对NeRF的升级,毫末表示可以做到重建误差小于10cm,并且对于场景中的动态物体也能做到很好的重建和渲染,达到肉眼基本看不出差异的程度。
由于单趟重建有时会受到遮挡的影响,毫末也尝试了多趟重建的方式。即多辆车在不同时间经过同一地方,可以将数据合在一起做多趟重建。目前毫末已经实现了更高的场景还原度,重建效率提升5倍,同时,还可在重建之后编辑场景合成难以收集的Corner Case。
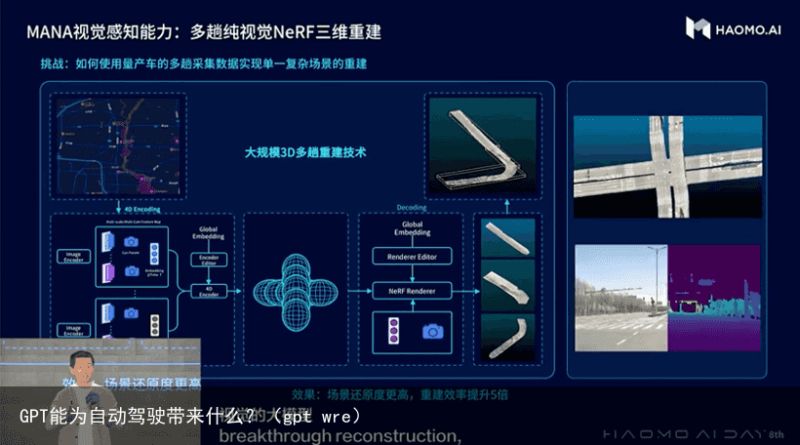 图片来源:毫末智行
图片来源:毫末智行
结语:
从毫末的布局中,我们也可以窥见自动驾驶行业的一动向。
首先,汽车行业价格战的影响已经传导至上游智驾供应链领域,“降本”成为重中之重,毫末在AI DAY中表示,要用1/3的成本做同等功能的方案。
在降本的压力之下,高精地图,甚至激光雷达这种高价格的产品都在逐渐被抛弃。在辅助驾驶领域,玩家都在向特斯拉看齐,走轻地图和纯视觉的道路。
另外,除感知之外,行业还越来越重视决策规划。感知尚可以用硬件堆砌,做决策规划则是综合能力的硬比拼,包括算力等基础设施、真实的道路数据和数据处理能力、算法模型等等。总之,辅助驾驶领域的竞争,已经越来越残酷了。
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP 随机内容
-
 美国又一辆载有危险品的火车出轨,附近居民被警告“远离”(美国火车有安检吗)
美国又一辆载有危险品的火车出轨,附近居民被警告“远离”(美国火车有安检吗)
-
 初中语法精讲1 过去进行时,中考重难点!(初中英语过去进行时)
初中语法精讲1 过去进行时,中考重难点!(初中英语过去进行时)
-
 自己动手洗车也有小妙招,做到这“六个不要”,干净洗车又安全!(自己洗车窍门)
自己动手洗车也有小妙招,做到这“六个不要”,干净洗车又安全!(自己洗车窍门)
-
 教你如何自己动手车打蜡,其实很简单!最后介绍2分钟打蜡方法!(汽车自己怎样打蜡)
教你如何自己动手车打蜡,其实很简单!最后介绍2分钟打蜡方法!(汽车自己怎样打蜡)
-
 总投资10.5亿元,杭州智能设备生产基地正式开工,智能洗车龙头品牌驿公里即将实现产能飞跃(杭州洗车设备有限公司)
总投资10.5亿元,杭州智能设备生产基地正式开工,智能洗车龙头品牌驿公里即将实现产能飞跃(杭州洗车设备有限公司)
-
 质用车:动手的乐趣 家用洗车机该如何选?(家用洗车机哪款好用又实惠)
质用车:动手的乐趣 家用洗车机该如何选?(家用洗车机哪款好用又实惠)
-
 外面洗车成本高?不如试试自己洗车,省钱又省心(外面洗车一般多少钱)
外面洗车成本高?不如试试自己洗车,省钱又省心(外面洗车一般多少钱)
-
 山东老板开洗车店,利用“洗车免费不要钱”,一年盈利300万,牛(洗车行老板)
山东老板开洗车店,利用“洗车免费不要钱”,一年盈利300万,牛(洗车行老板)
-
加油站安装自动洗车机,该怎么选择?(加油站自动洗车机注意事项)
-
我们曝出的设计缺陷,两年后这辆新车上改进了 前保时捷设计师+对开门,1300马力+3秒破百,中国造!2023上海车展探馆:奇瑞捷豹XFL鎏金版2023上海车展探馆:红旗E0012023上海车展探馆:红
